.png)
Build, manage and deploy auto-adaptive models
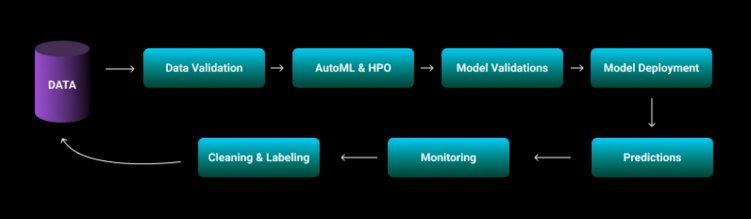
This webinar will instruct data scientists and machine learning engineers how to build manage and deploy auto-adaptive machine learning models in production. Data is ever changing, leaving your models outdated and built on old data. This can lead to underperforming models and a lot of manual work to fix it. By allowing your models to continually learn you’ll ensure that they run at peak performance. Using state of the art Kubernetes infrastructure, we’ll show you how to automatically track and manage your auto-adaptive machine learning models while in production. By building auto-adaptive machine learning models, data engineers can bridge the gap between research and production. After this webinar you’ll be able to build and deploy machine learning pipelines that automatically adapt and retrain based on any validation trigger you choose.
Key webinar takeaways:
- How to build auto-adaptive machine learning pipelines
- How to use Kubernetes to manage and scale models in production
- How to automatically monitor for peak performance
- How to set up continuous deployment of ML pipeline